Query data from the IIASA database infrastructure¶
The IIASA Energy, Climate, and Environment Program hosts a suite of Scenario Explorer instances and related database infrastructure to support analysis of integrated-assessment pathways in IPCC reports and model comparison projects. High-profile use cases include the AR6 Scenario Explorer hosted by IIASA supporting the IPCC’ Sixth Assessment Report (AR6) and the Horizon 2020 project ENGAGE.
IIASA’s modeling platform infrastructure and the scenario apps are not only a great resource on its own, but it also allows the underlying datasets to be queried directly via a Rest API. The pyam package takes advantage of this ability to allow you to easily pull data and work with it in your Python data processing and analysis workflow.
Access and permission management for project-internal databases¶
By default, your can connect to all public scenario database instances.
ixmp4 login <username>
You will be prompted to enter your password.
Your username and password will be saved locally in plain-text for future use!
When connecting to a database, pyam will automatically search for the configuration in a known location.
[1]:
import pyam
Connecting to ixmp4 platforms (database instances) hosted by IIASA¶
The Scenario Apps use the ixmp4 package as a database backend.
You can get an overview of all accessible platforms hosted by IIASA using pyam.iiasa.platforms().
[2]:
pyam.iiasa.platforms()
[INFO] 18:44:07 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:08 - pyam.iiasa: Platforms accessible via https://api.manager.ece.iiasa.ac.at/v1
[2]:
| name | slug | accessibility | notice | |
|---|---|---|---|---|
| 0 | Public Testing Instance | public-test | PUBLIC | This is a public ixmp4 test instance. |
| 1 | ECEMF | ecemf | PUBLIC | This is the public database instance for the H... |
| 2 | SSP Extensions | ssp-extensions | PUBLIC | This is the SSP-Extensions project database. A... |
| 3 | SSP Scenario Explorer | ssp | PUBLIC | This platform has the scenarios and "basic dri... |
| 4 | State of CDR (SoCDR) Data Portal - Edition 2, ... | socdr | PUBLIC | This platform contains the data for the "State... |
| 5 | SHAPE | shape | PUBLIC | This database has key scenarios developed by t... |
| 6 | NAVIGATE | navigate | PUBLIC | This platform contains the data for the "NAVIG... |
| 7 | GENIE | genie | PUBLIC | GENIE Knowledge Hubs |
| 8 | ELEVATE | elevate | PUBLIC | This is the public database instance for the H... |
| 9 | Playground Public | playground-public | PUBLIC | |
| 10 | Ariadne2 | ariadne2 | PUBLIC | This is the public database instance for the s... |
| 11 | SPARCCLE | sparccle | PUBLIC | This platform contains the data for the "SPARC... |
| 12 | IDesignRES | idesignres | PUBLIC | This platform contains the data for the "IDesi... |
| 13 | Global Environment Outlook 7 (GEO7) | geo7 | PUBLIC | This database has key scenarios developed for ... |
| 14 | SSP 2018 Release | ssp-2018 | PUBLIC | This platform has scenario data for the Shared... |
| 15 | Austrian energy and emissions scenarios | energy-scenarios-at | PUBLIC | |
| 16 | Scenario Compass | scenariocompass | PUBLIC | This is the public platform for the Scenario C... |
| 17 | UNEP-FI Climate Pathways Navigator | unep-fi | PUBLIC | This is the database platform for the "Climate... |
| 18 | CircEUlar | circeular | PUBLIC | This is a public instance for the CircEUlar pr... |
| 19 | Indicators of Global Climate Change(IGCC) 2025 | igcc-2025 | PUBLIC | This is the platform for the Indicators of Glo... |
| 20 | PRISMA | prisma | PUBLIC | This is a public instance for the PRISMA project |
Connecting to a (legacy) Scenario Explorer database¶
Accessing the database connected to a Scenario Explorer is done via a Connection object.
[3]:
conn = pyam.iiasa.Connection()
conn.valid_connections
[INFO] 18:44:08 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:08 - pyam.iiasa: You are connected as an anonymous user
[WARNING] 18:44:08 - pyam.iiasa: IIASA is migrating to a database infrastructure using the ixmp4 package.Use `pyam.iiasa.platforms()` to list available ixmp4 databases.
[3]:
['nca5',
'nmsf',
'ar6-public',
'ecemf',
'openentrance',
'ariadne2',
'hotspots',
'circomod',
'geidco',
'guide',
'ngfs_phase_2',
'ngfs_phase_5_short_term',
'kopernikus_public',
'ngfs_phase_5',
'ariadne',
'engage',
'commit',
'genie',
'climate_solutions',
'senses',
'ssp',
'ngfs_phase_3',
'eu-climate-advisory-board',
'set_nav',
'guide_internal',
'cdlinks',
'aqnea',
'integration-test',
'ripples',
'ar6',
'netzero2040',
'paris_lttg',
'ngfs_phase_4',
'nexus_basins',
'india_scenario_hub',
'deeds',
'gei',
'ar6_sandbox',
'iamc15']
Reading data from a database hosted by IIASA¶
In this example, we will be retrieving data from the IAMC 1.5°C Scenario Explorer hosted by IIASA (link), which provides the quantitative scenario ensemble underpinning the IPCC Special Report on Global Warming of 1.5C (SR15).
This can be done either via the constructor:
pyam.iiasa.Connection('iamc15')
or, if you want to query multiple databases, via the explicit connect() method:
conn = pyam.iiasa.Connection()
conn.connect('iamc15')
We also provide some convenience functions to shorten the amount of code you have to write. Under the hood, read_iiasa() is just opening a connection to a database API and sends a query to the resource.
In this tutorial, we will query specific subsets of data in a manner similar to pyam.IamDataFrame.filter().
[4]:
df = pyam.read_iiasa(
"iamc15",
model="MESSAGEix*",
variable=["Emissions|CO2", "Primary Energy|Coal"],
region="World",
meta=["category"],
)
[INFO] 18:44:08 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:09 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:11 - pyam.iiasa: You are connected to the IXSE_SR15 scenario explorer hosted by IIASA. If you use this data in any published format, please cite the data as provided in the explorer guidelines: https://data.ece.iiasa.ac.at/iamc-1.5c-explorer/#/about
[INFO] 18:44:11 - pyam.iiasa: You are connected as an anonymous user
Here we pulled out all times series data for model(s) that start with ‘MESSAGEix’ that are in the ‘World’ region and associated with the two named variables. We also added the meta column “category”, which tells us the climate impact categorisation of each scenario as assessed in the IPCC SR15.
Let’s plot CO2 emissions.
[5]:
ax = df.filter(variable="Emissions|CO2").plot(
color="category", legend=dict(loc="center left", bbox_to_anchor=(1.0, 0.5))
)
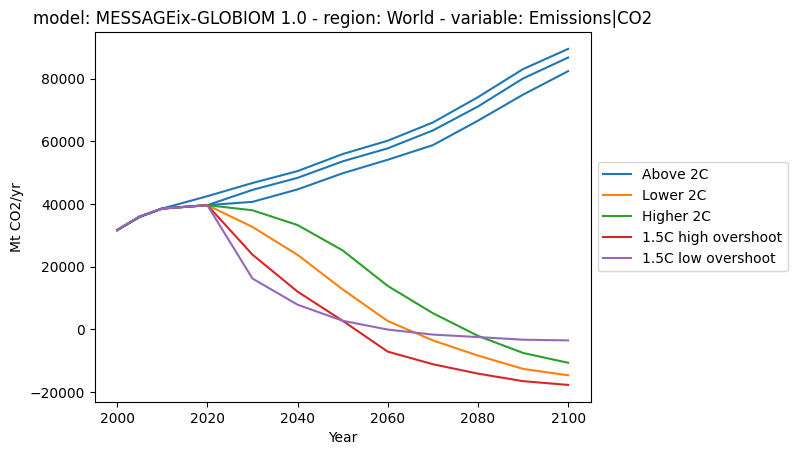
And now continue doing all of your analysis!
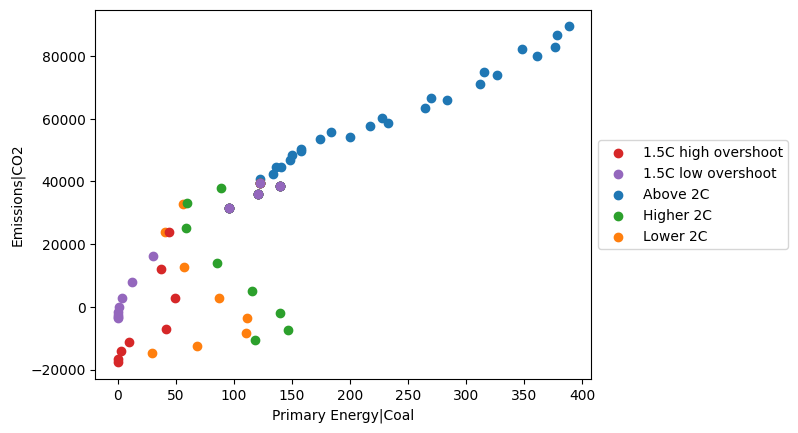
[6]:
ax = df.plot.scatter(
x="Primary Energy|Coal",
y="Emissions|CO2",
color="category",
legend=dict(loc="center left", bbox_to_anchor=(1.0, 0.5)),
)
Exploring the data resource¶
If you’re interested in what data is available in the data source, you can use pyam.iiasa.Connection to do so.
[7]:
conn = pyam.iiasa.Connection("iamc15")
[INFO] 18:44:15 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:16 - pyam.iiasa: You are connected to the IXSE_SR15 scenario explorer hosted by IIASA. If you use this data in any published format, please cite the data as provided in the explorer guidelines: https://data.ece.iiasa.ac.at/iamc-1.5c-explorer/#/about
[INFO] 18:44:16 - pyam.iiasa: You are connected as an anonymous user
The Connection object has a number of useful functions for listing what’s available in the data resource. These functions follow the conventions of the IamDataFrame class (where possible).
A few of them are shown below.
[8]:
conn.models().head()
[8]:
0 AIM/CGE 2.0
1 AIM/CGE 2.1
2 C-ROADS-5.005
3 GCAM 4.2
4 GENeSYS-MOD 1.0
Name: model, dtype: object
[9]:
conn.scenarios().head()
[9]:
0 ADVANCE_2020_1.5C-2100
1 ADVANCE_2020_Med2C
2 ADVANCE_2020_WB2C
3 ADVANCE_2030_Med2C
4 ADVANCE_2030_Price1.5C
Name: scenario, dtype: object
[10]:
conn.variables().head()
[10]:
0 AR5 climate diagnostics|Concentration|CO2|FAIR...
1 AR5 climate diagnostics|Concentration|CO2|MAGI...
2 AR5 climate diagnostics|Forcing|Aerosol|Direct...
3 AR5 climate diagnostics|Forcing|Aerosol|MAGICC...
4 AR5 climate diagnostics|Forcing|Aerosol|Total|...
Name: variable, dtype: object
[11]:
conn.regions().head()
[11]:
0 World
1 R5ROWO
2 R5ASIA
3 R5LAM
4 R5MAF
Name: region, dtype: object
We queried the meta-indicator “category” in the above example, but there are many more. You can get a list with the following command:
[12]:
conn.meta_columns.head()
[12]:
0 Kyoto-GHG|2010 (SAR)
1 baseline
2 carbon price|2030
3 carbon price|2030 (NPV)
4 carbon price|2050
Name: name, dtype: object
You can directly query the Connection, which will return a pyam.IamDataFrame…
[13]:
df = conn.query(
model="MESSAGEix*",
variable=["Emissions|CO2", "Primary Energy|Coal"],
region="World",
)
…so that you can directly continue with your analysis and visualization workflow using pyam!
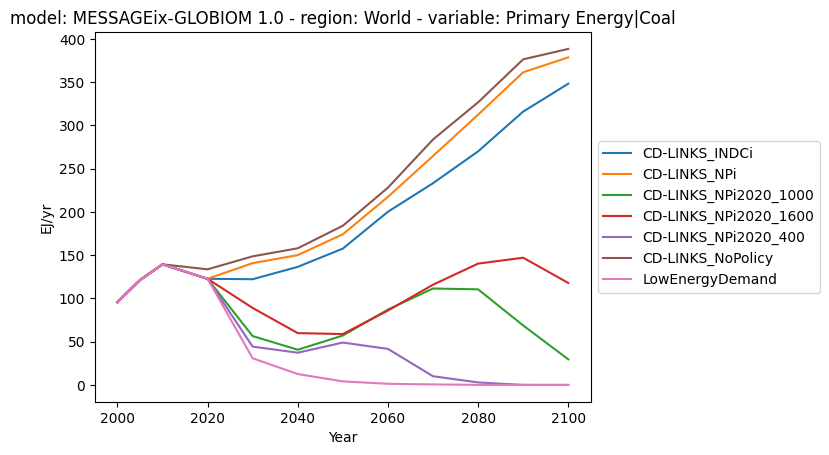
[14]:
ax = df.filter(variable="Primary Energy|Coal").plot(
color="scenario", legend=dict(loc="center left", bbox_to_anchor=(1.0, 0.5))
)
Loading all of a large database may take a few minutes on some connections. To save time when writing code you may reuse, you can save a local version of the database via the lazy_read_iiasa function. This is given a file location as well as whatever connection options we saw above. The first time the code is run, the result is stored there, and the code will read it from there on subsequent attempts.
[15]:
lazy_df = pyam.lazy_read_iiasa(
file="./tmp/messageix_co2_coal_data.csv",
name="iamc15",
model="MESSAGEix*",
variable=["Emissions|CO2", "Primary Energy|Coal"],
region="World",
)
[INFO] 18:44:23 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:24 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:26 - ixmp4.conf.settings: Using anonymous http authentication strategy because no local credentials were found.
[INFO] 18:44:27 - pyam.iiasa: You are connected to the IXSE_SR15 scenario explorer hosted by IIASA. If you use this data in any published format, please cite the data as provided in the explorer guidelines: https://data.ece.iiasa.ac.at/iamc-1.5c-explorer/#/about
[INFO] 18:44:27 - pyam.iiasa: You are connected as an anonymous user
[ ]: